파이썬 3일차
피벗테이블 생성하기
# pivot/pivot_table을 위한 데이터프레임 만들기
import pandas as pd
import numpy as np
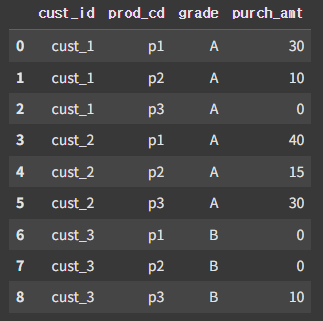
pivot_data = pd.DataFrame({'cust_id' : ['cust_1', 'cust_1', 'cust_1', 'cust_2', 'cust_2', 'cust_2', 'cust_3', 'cust_3', 'cust_3'],
'prod_cd' : ['p1', 'p2', 'p3', 'p1', 'p2', 'p3', 'p1', 'p2', 'p3'],
'grade' : ['A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B'],
'purch_amt' : [30, 10, 0, 40, 15, 30, 0, 0, 10]})기준 데이터
# pivot 활용하기
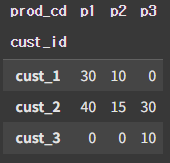
pivot_data.pivot(index='cust_id', columns='prod_cd', values='purch_amt')피벗 = 중복값이 없을때 cust_id를 인덱스로, prod_cd를 컬럼으로, purch_amt를 값으로 사용한다.
# 중복값이 존재하는 경우 에러 메시지
pivot_data.pivot(index='grade', columns='prod_cd', values='purch_amt')
피벗의 경우 중복값이 존재하면 에러가 발생한다.
# pivot_table 활용하기
pivot_data.pivot_table(index='grade', columns='prod_cd', values='purch_amt')
피벗테이블은 중복과 무관하게 사용할수 있다.
# pivot_table의 aggfunc 지정하기
pivot_data.pivot_table(index='grade', columns='prod_cd', values='purch_amt', aggfunc=np.sum)
aggfunc의 기본값은 '평균'이지만 따로 지정할수도 있다.
위의 예시는 '합계'로 지정한 것이다.
인덱스 및 칼럼 레벨 변경하기
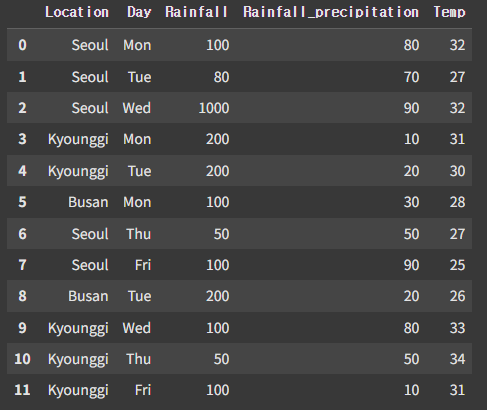
stack_data = pd.DataFrame({
'Location' : ['Seoul', 'Seoul', 'Seoul', 'Kyounggi', 'Kyounggi', 'Busan', 'Seoul', 'Seoul', 'Busan', 'Kyounggi', 'Kyounggi', 'Kyounggi'],
'Day' : ['Mon', 'Tue', 'Wed', 'Mon', 'Tue', 'Mon', 'Thu', 'Fri', 'Tue', 'Wed', 'Thu', 'Fri'],
'Rainfall' : [100, 80, 1000, 200, 200, 100, 50, 100, 200, 100, 50, 100],
'Rainfall_precipitation' : [80, 70, 90, 10, 20, 30, 50,90, 20, 80, 50, 10],
'Temp' : [32, 27, 32 ,31, 30, 28,27, 25,26, 33, 34, 31]})기준데이터
new_stack_data = stack_data.set_index(['Location', 'Day'])
new_stack_data
Location과 Day를 인덱스로 데이터프레임을 설정했다.
# unstack 확인하기
new_stack_data.unstack(0)
unstack에 의해 0번 인덱스에 있던 Location이 컬럼줄로 올라갔다.
new_stack_data.unstack(1)
이번에는 unstack에 의해 1번에 있던 Day가 컬럼줄로 올라갔다.
따라서 stack(n)은 n번째 컬럼을 인덱스로 내리고, unstack(n)은 n번째 인덱스를 칼럼줄로 올린다.
new_stack_data2 = new_stack_data.unstack(1)
new_stack_data2.stack(1)
이번에는 1번 인덱스 Day를 컬럼으로 올렸다가 다시 인덱스로 내렸다.
이로 인해서 원상복구가 이루어졌다.
데이터프레임 병합하기
# concat 실행을 위한 데이터프레임 만들기
import pandas as pd
import numpy as np
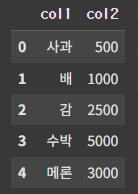
df1 = pd.DataFrame({'col1' : ['사과', '배', '감', '수박', '메론'],
'col2' : [500, 1000, 2500, 5000, 3000]
}, index=[0,1,2,3,4])
df2 = pd.DataFrame({'col1' : ['수박', '메론', '딸기', '키위', '오렌지'],
'col2' : [5000, 3000, 1000, 600, 700]
}, index=[3,4,5,6,7])기준데이터
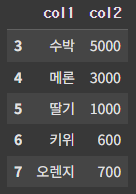
# ignore_index 확인하기
pd.concat([df1, df2], ignore_index=False)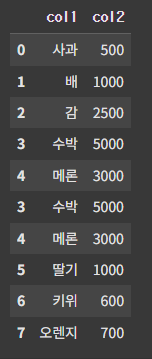
concat은 데이터프레임을 세로로 병합시킨다. 이때 ignore_index가 False이면 인덱스를 유지한다.
pd.concat([df1, df2], ignore_index=True)
ignore_index가 True면 인덱스를 다시 붙인다.
# concat axis 이해하기
pd.concat([df1, df2], axis=1)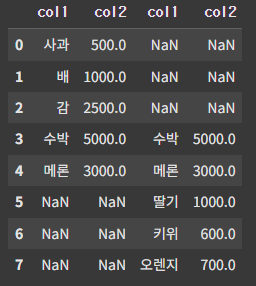
axis가 0이거나 없으면 디폴트로 위의 예제와 같은 결과가 나오고, axis가 1이면 동일한 인덱스는 나란히, 다른 인덱스는 NaN과 함께 출력된다.
df3 = pd.DataFrame({
'item' : ['item0', 'item1', 'item2', 'item3'],
'count' : ['count0', 'count1', 'count2', 'count3'],
'price' : ['price0', 'price1', 'price2', 'price3']}, index=[0,1,2,3])
df4 = pd.DataFrame({
'item' : ['item2', 'item3', 'item4', 'item5'],
'count' : ['count2', 'count3', 'count4', 'count5'],
'price' : ['price2', 'price3', 'price4', 'price5'],
'var' : ['var2', 'var3', 'var4', 'vat5']}, index=[2,3,4,5])기준데이터

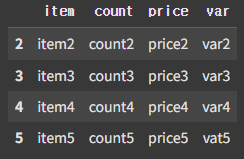
# join의 outer 방식
pd.concat([df3, df4], join='outer')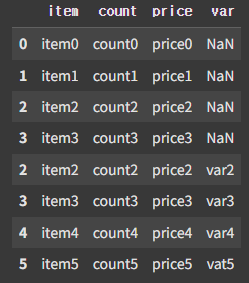
outer join은 합집합 방식으로 모두 병합하고, 값이 없으면 NaN으로 표시한다.
# join의 inner 방식
pd.concat([df3, df4], join='inner')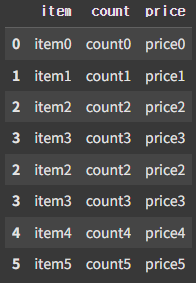
inner join은 교집합 방식으로 두 데이터에 공통으로 존재하는 칼럼만 병합한다.
인덱스가 중복일 경우
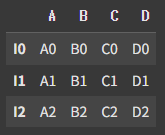
df5 = pd.DataFrame({
'A' : ['A0', 'A1', 'A2'],
'B' : ['B0', 'B1', 'B2'],
'C' : ['C0', 'C1', 'C2'],
'D' : ['D0', 'D1', 'D2']}, index=['I0', 'I1', 'I2'])
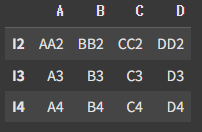
df6 = pd.DataFrame({
'A' : ['AA2', 'A3', 'A4'],
'B' : ['BB2', 'B3', 'B4'],
'C' : ['CC2', 'C3', 'C4'],
'D' : ['DD2', 'D3', 'D4']}, index=['I2', 'I3', 'I4'])기준데이터
# verify_integrity 확인하기(에러 메시지)
pd.concat([df5, df6], verify_integrity=True)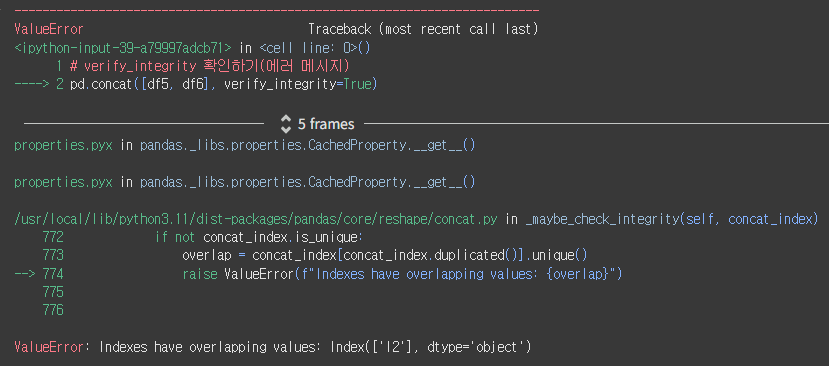
verify_integrity=True 일때, 인덱스가 중복되면 에러가 발생한다.
해당 코드에서는 'I2' 인덱스가 중복되었기 때문에 에러가 발생했다.
import pandas as pd
import numpy as np
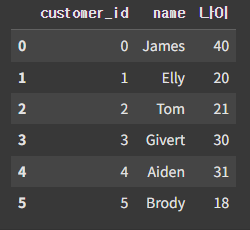
customer = pd.DataFrame({'customer_id' : np.arange(6),
'name' : ['James', 'Elly', 'Tom', 'Givert', 'Aiden', 'Brody'],
'나이' : [40, 20, 21, 30, 31, 18]})
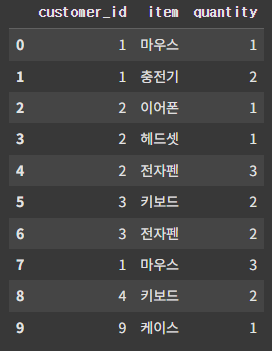
orders = pd.DataFrame({'customer_id' : [1, 1, 2, 2, 2, 3, 3, 1, 4, 9],
'item' : ['마우스', '충전기', '이어폰', '헤드셋', '전자펜', '키보드', '전자펜', '마우스', '키보드', '케이스'],
'quantity' : [1, 2, 1, 1, 3, 2, 2, 3, 2, 1]})기준데이터
# merge 함수의 on 속성 이해하기(기준이 서로 다르면 left_on, right_on으로 적용가능)
pd.merge(customer, orders, on='customer_id')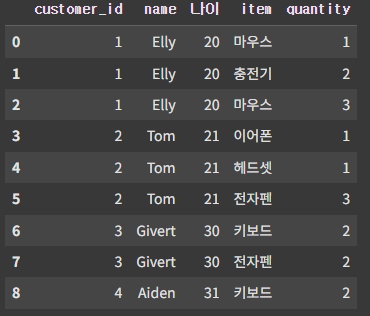
merge를 활용하여 customer와 orders 데이터를 'customer_id'라는 공통된 컬럼을 기준으로 병합한다.
병합될때 왼쪽에 있던 customer가 왼쪽, orders는 오른쪽에 붙으며
기준이 되는 칼럼의 이름이 서로 다를경우 rename을 하거나, on을 left_on, right_on을 이용해서 일치하는 칼럼을 맞춘다.
예시) left_on='id', right_on='customer_id'
# merge 함수의 how 속성 이해 하기
pd.merge(customer, orders, on='customer_id', how='inner')
how 파라미터는 merge의 방식을 정의한다.
- inner : 일치하는 값이 있는 경우에만 데이터를 가져온다.
- left : 왼쪽 데이터를 기준으로 데이터를 병합한다.(오른쪽에 없으면 NaN)
- right : 오른쪽 데이터를 기준으로 데이터를 병합한다.(왼쪽에 없으면 NaN)
- outer : left와 right를 합한 데이터프레임을 병합한다.
# 인덱스를 지정하여 데이터프레임 합치기
cust1 = customer.set_index('customer_id')
order1 = orders.set_index('customer_id')
pd.merge(cust1, order1, left_index=True, right_index=True) # → join()과 비슷
왼쪽 데이터의 인덱스와 오른쪽 데이터의 인덱스 모두 포함되는 데이터를 병합한다.
결과는 inner와 같다.