다변량 시각화
산점도
plt.figure(figsize=(16,8))
# price와 duration의 산점도 그리기
plt.scatter(y=df['price'], x=df['duration'])
plt.xlabel('Duration')
plt.ylabel('Price')
plt.show()
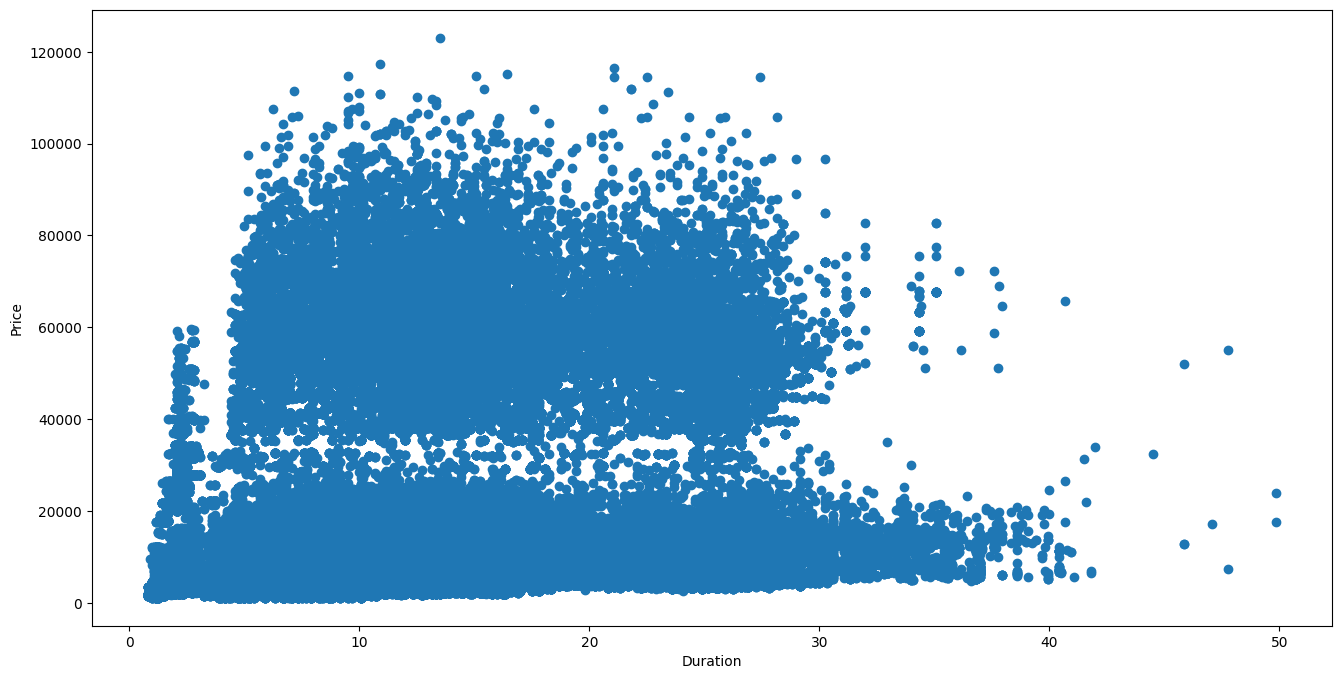
비행시간과 항공권 가격의 관계를 나타내었다.
산점도는 2개의 연속형 변수의 관계를 보기 위해서 X축과 Y축에 표시하는 점들을 찍어서 만드는 그래프이다.
산점도에 표기되는 점들은 자료들의 관측값을 나타내며, 키와 몸무게와 같은 두 변수 간의 상관관계를 대략적으로 확인할수있다.
plt.figure(figsize=(16,6))
# "Economy" Class에 대한 price와 duration 간의 산점도 그리기
plt.scatter(y=df_eco['price'], x=df_eco['duration'])
plt.xlabel('Duration')
plt.ylabel('Price')
plt.show()

이코노미 클래스만 한정하여 찍은 산점도이다.
히트맵
# numpy 불러오기
import numpy as np
# 상관계수 데이터 만들기
heat = df_eco.corr(numeric_only=True)
# 상관계수로 heatmap 그리기
plt.pcolor(heat)
# X축 항목 정보 표시하기
plt.xticks(np.arange(0.5, len(heat.columns), 1), heat.columns)
# Y축 항목 정보 표시하기
plt.yticks(np.arange(0.5, len(heat.index), 1), heat.index)
# 히트맵 확인을 위한 컬러바 표시하기
plt.colorbar()
plt.show()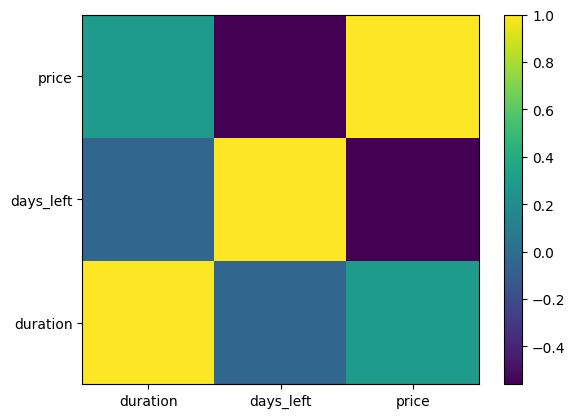
히트맵은 여러 카테고리 값의 변화를 한눈에 볼 수 있기 때문에 두 값 또는 각 칼럼 간의 상관관계를 나타낼때 주로 사용한다.
상관계수를 색깔로 표현하고 우측의 컬러바를 통해서 값을 알수있다.
seaborn 시각화 라이브러리 활용하기
범주형 산점도
# seaborn이 기본 설치되어 있지 않은 작업 환경에서는 아래 줄의 #을 삭제 후 seaborn 설치
# %pip install seaborn
# seaborn 불러오기
import seaborn as sns
#airline 별 price를 class로 구분하여 시각화하기
sns.catplot(y='airline', x='price', col='class', data=df, palette='Set2')
범주형 데이터와 수치형 데이터의 관계를 시각화 할 수 있는 그래프이다.
row, col, hue 파라미터를 사용해서 더 많은 범주형 데이터 관계를 확인할 수 있다.
선형 회귀 모델 그래프
# duration과 price의 회귀선을 빨간색으로 표시해서 시각화하기
sns.lmplot(x='duration', y='price', data=df_eco, line_kws={'color': 'red'})
선형 회귀 모델과 연관 있는 함수로 일반적인 산점도와 함께 직선의 회귀선을 그려주어 특성간의 선형적인 관계를 확인하기 쉬운 그래프이다.
빈도 그래프
# 항공권 데이터의 빈도를 airline으로 구분하여 class 별로 시각화하기
sns.countplot(x='airline', hue='class', data=df)
범주형 데이터에 대하여 항목별 개수를 세어서 막대 그래프를 그린다.
각 카테고리 값별로 데이터가 얼마나 있는지 표시할 수 있으며, 해당 특성을 구성하고 있는 값을 구분해서 보여준다.
조인트 그래프
# price와 duration의 관계를 조인트 그래프로 시각화하기
sns.jointplot(x='duration', y='price', data=df_eco)
중앙의 산점도 그래프의 가장자리의 히스토그램을 동시에 그려주는 그래프이다.
데이터의 분포와 상관관계를 한번에 볼 수 있지만 수치형 데이터만 표현할 수 있다.
히트맵
# 상관계수로 heatmap 그리기
sns.heatmap(df_eco.corr(numeric_only=True), annot=True)
이전과 동일하게 히트맵이고, 더 쉽게 그릴수 있다.
수치형 데이터 정제하기
# 판다스 불러오기
import pandas as pd
# 데이터 읽어오기
df = pd.read_csv('Clean_Dataset.csv')
# 지정 인덱스인 첫 번째 칼럼 삭제하기
df.drop([df.columns[0]], axis=1, inplace=True)초기 세팅
# 랜덤하게 결측치 생성하기
# 랜덤과 넘파이 불러오기
import random
import numpy as np
# 같은 결과 출력을 위해 시드 고정하기
random.seed(2023)
np.random.seed(2023)
# 랜덤한 위치에서 결측치 5,000개를 포함한 데이터 df_na 생성하기(결측치 5,000개 생성)
df_na = df.copy()
for i in range(0, 5000) :
df_na.iloc[random.randint(0, 300152), random.randint(0, 10)] = np.nan
# 결측치 처리 여부 확인을 위한 1번, 3번 인덱스 전체 결측치 처리하기(2개 결측치 생성)
df_na.iloc[1] = np.nan
df_na.iloc[3] = np.nan기존의 클린데이터의 경우에는 결측치가 없기 때문에 일부러 결측치를 만들어준다.
# 데이터 정보 확인하기
df_na.info()
결측치가 반영된 데이터의 모습이다.
# 결측치 수 확인하기
df_na.isnull().sum(axis=0)
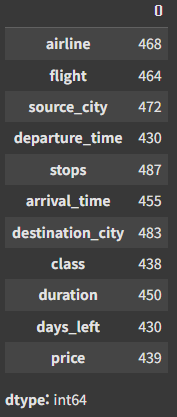
각 컬럼 별로 결측치가 발생한 갯수이다.
# 데이터 변경에 대비하여 원본 데이터 복사하기
df_na_origin = df_na.copy()결측치가 반영된 데이터를 복사해둔다.
결측치 삭제하기
# 결측치를 하나라도 가지는 행 모두 삭제하기
df_na = df_na.dropna()
df_na.info()
결측치를 가지는 모든 행을 삭제했다.
원래 300153개의 데이터가 295192개로 줄었다.
# 결측치 삭제하기 전 원래 데이터 가져오기
df_na = df_na_origin.copy()
# 모든 데이터가 결측치인 행만 삭제하기
df_na = df_na.dropna(how='all')
df_na.info()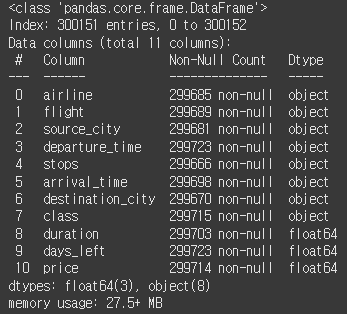
이번에는 모든 데이터가 결측치인 행만 삭제한다.
아까보다 데이터 손실이 적다.
# 결측치 삭제하기 전 원래 데이터 가져오기
df_na = df_na_origin.copy()
# stops와 flight 제거하기
df_na = df_na.drop(['stops', 'flight'], axis=1)
df_na.info()
선택한 컬럼만 삭제하기
# 결측치를 하나라도 가지는 행 모두 삭제하기
df_na = df_na.dropna()
df_na.info()
결측치를 하나라도 가지는 행 삭제하기
모든 결측치를 가진 행을 삭제하는것과 동일하지만, 컬럼이 2개 없어진 후라 갯수 차이가 난다.
결측치 대체하기
df_na = df_na_origin.copy()
# 칼럼별 평균값으로 결측치 대체하기
df_na = df_na.fillna(df_na.mean(numeric_only=True))
df_na.info()
이번 방법은 결측치를 삭제하지 않고, 대신 평균값을 넣는 방식이다.
이로 인해 데이터 손실은 발생하지 않는다.
# 0번 인덱스부터 5개의 데이터를 불러와서 1번, 3번 인덱스 삭제 결과 확인하기
df_na.head()
행에 NaN이 포함되어 있지만 수치형 데이터를 평균치로 채워넣어 사라지지 않았다.
df_na = df_na.ffill()
df_na.info()
이 방식은 위와 비슷해보이지만 범주형 데이터도 채워준다.
# 0번 인덱스부터 5개의 데이터를 불러와서 1번, 3번 인덱스 삭제 결과 확인하기
df_na.head()

아까와는 다르게 수치형 데이터 뿐만 아니라 범주형 데이터도 채워졌다.
이상치 파악하기
이상치는 제1사분위보다 -25%보다 작은 값, 제3사분위보다 25% 큰 값을 의미한다.
# Z-score를 기준으로 신뢰 수준이 95%인 데이터 확인하기
df[(abs((df['price'] - df['price'].mean(numeric_only=True))/df['price'].std())) > 1.96].head()
위의 코드는 Z-score를 이용하여 신뢰 수준이 95% 이상인 데이터만 확인하는 방법이다

i번째 데이터에서 전체 평균을 빼고 그 값을 표준편차로 나누는 방식이다.
# IQR 기준 이상치 확인하는 함수 만들기
def findOutliers(x, column):
# 제1사분위수 q1구하기
q1 = x[column].quantile(0.25)
# 제3사분위수 q1구하기
q3 = x[column].quantile(0.75)
# IQR의 1.5배수 IQR 구하기
iqr = 1.5 * (q3 - q1)
# 제3사분위수에서 IQR의 1.5배보다 크거나 제1사분위수에서 IQR의 1.5배보다 작은 값만 저장한 데이터 y 만들기
y = x[(x[column] > (q3 + iqr)) | (x[column] < (q1 - iqr))]
# IQR 기준 이상치 y 반환하기
return len(y)이 코드는 IQR을 기준으로 이상치에 해당하는 값들을 반환하는 함수이다.
# price, duration, days_left에 대하여 IQR 기준 이상치 개수 확인하기
print('price IQR Outliers :',findOutliers(df, 'price'))
print('duration IQR Outliers :',findOutliers(df, 'duration'))
print('days_left IQR Outliers :',findOutliers(df, 'days_left'))
만들어낸 함수를 이용해서 각 컬럼에 이상치가 얼마나 있는지 도출한다.