# 시각화를 위해 matplotlib.pyplot 불러오기
import matplotlib.pyplot as plt
plt.figure()
# 첫 번째 subplot : 1행 5열로 나눈 영역에서 첫 번째 영역
plt.subplot(151)
df[['duration']].boxplot()
plt.ylabel('Time')
# 두 번째 subplot : 1행 5열로 나눈 영역에서 세 번째 영역
plt.subplot(153)
df[['days_left']].boxplot()
plt.ylabel('Days')
# 세 번째 subplot : 1행 5열로 나눈 영역에서 다섯 번째 영역
plt.subplot(155)
df[['price']].boxplot()
plt.ylabel('Price')
plt.show()
이상치가 있었던 데이터를 상자그래프로 나타내어 duration과 price 칼럼에 이상치가 있는걸 확인할 수 있다.
# 데이터 변형에 대비하여 데이터 원본 복사하기
df_origin = df.copy()
# 신뢰도 95% 기준 이상치 Index 추출하기
outlier = df[(abs((df['price'] - df['price'].mean(numeric_only=True))/df['price'].std())) > 1.96].index
# 추출한 인덱스의 행 삭제해서 clean_df 데이터 만들기
clean_df = df.drop(outlier)
clean_df.info()
신뢰도가 95% 이상인 index만 남기고 제거했다.
plt.figure(figsize=(4,5))
# 상자 그래프 활용하여 이상치 제거 여부 확인하기
clean_df[['price']].boxplot()
plt.show()
신뢰도가 95% 이상인 데이터만 남기니까 이상치 없이 깨끗한 그래프가 그려졌다.
# IQR 기준 이상치를 대체하는 함수 만들기
def ChangeOutlier(x, column):
# 제1사분위수 q1 구하기
q1 = x[column].quantile(0.25)
# 제3사분위수 q3 구하기
q3 = x[column].quantile(0.75)
# IQR의 1.5배수 IQR 구하기
iqr = 1.5 * (q3 - q1)
# 이상치를 대체 할 Min, Max 값 설정하기
Min = (q1 - iqr)
Max = q3 + iqr
# Max보다 큰 값은 Max로, Min보다 작은 값은 Min으로 대체하기
x.loc[(x[column] > Max), column] = Max
x.loc[(x[column] < Min), column] = Min
# x리턴하기
return(x)
# price에 대하여 이상치 대체하기
clean_df = ChangeOutlier(df, 'price')
clean_df.info()
이 함수는 기존의 NaN인 데이터를 지우지 않고, Max 보다 큰 이상치는 Max값으로, Min 보다 낮은 이상치는 Min 값으로 설정하는 함수이다.
이를 통해 데이터를 손실하지 않고 클린데이터를 얻을수 있다.
# price에 대하여 IQR 기준 이상치 개수 확인하기
print('price IQR Outliers :',findOutliers(clean_df, 'price'))
plt.figure(figsize=(4,5))
# 상자 그래프 활용하여 이상치 대체 여부 확인하기
clean_df[['price']].boxplot()
plt.show()
이를 IQR을 이용해서 검사해보고, 상자그래프로도 나타내어도 이상치가 없는 클린한 데이터임을 알 수있다.
# 비행시간을 0~5, 5~10, 10 이상의 3개 구간으로 나누어 거리 칼럼 생성하기
df['distance'] = pd.cut(df['duration'], bins=[0,5,10,df['duration'].max()], labels=['short', 'medium', 'long'])
df.head(20)
비행시간 duration에 대해서 0~5, 5~10 10이상의 구간으로 나누고 새로 distance라는 칼럼을 생성하여 short, medium, long으로 구분했다.
df['distance'].value_counts()
총 300153개의 데이터 중 long은 169879개, medium은 84761개, short는 45513개로 집계 되었다.
# 항공권 가격을 4개 구간으로 동일하게 나누어 항공권 가격 비율 칼럼 생성하기
df['price_rate'] = pd.qcut(df['price'], 4, labels=['cheap', 'normal', 'expensive', 'too expensive'])
df.head(30)
이번에는 수치를 기준으로 하지 않고 구간의 갯수로 분류했다.
구간은 총 4개로 cheap, normal, expansive, too expensive로 나뉘며, 따로 기준 없이 25%씩 나눠져서 분류된다.
# 항공권 가격 비율 칼럼의 빈도분포 확인하기
df['price_rate'].value_counts()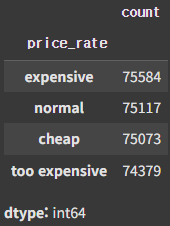
이론상으로 각 구간별로 데이터가 같은 숫자로 배분되어야하지만
중복된 값이 경계선이 몰려있거나, 소수점 자리수가 생략된 형태로 나타낼때 오차로 인해 미세한 차이가 발생한다.
현재 데이터는 이상치를 Min, Max 값으로 보정하였기 때문에 경계선에 데이터가 몰려있다.
범주형 데이터 정제하기
레이블 인코딩
# 데이터 구간화 전 원본 불러오기
df = df_origin.copy()
# factorize로 airline 칼럼 레이블 인코딩하기
df['airline_Label_Encoding'] = pd.factorize(df['airline'])[0].reshape(-1,1)
df.head(20)
데이터에서 airline을 기준으로 먼저 나오는 순으로 0번 부터 해서 레이블을 할당한다.
레이블은 동일한 데이터에 대해서 같은 수치로 표현된다.
# airline 칼럼과 새롭게 만들어진 label_encoding 칼럼의 빈도표 확인하기
print(df['airline'].value_counts())
print(df['airline_Label_Encoding'].value_counts())
빈도표를 살펴보면 해당하는 레이블과 항공사 이름의 빈도가 동일한것을 볼 수 있다.
# 사이킷런 패키지의 LabelEncoder 불러오기
from sklearn.preprocessing import LabelEncoder
# LabelEncoder로 airline 칼러 레이블 인코딩하기
le = LabelEncoder()
df['airline_Label_Encoding'] = le.fit_transform(df['airline'])
df.head()
이 방법은 사이킷런을 이용한 방법이다.
사이킷런의 LabelEncoder 함수를 이용하면 간단하게 레이블 인코딩을 할 수 있다.
이 경우 알파벳 순으로 0번 부터 할당된다.
# 레이블 인코딩 역변환(디코딩)하기
le.inverse_transform(df['airline_Label_Encoding']).reshape(-1,1)
사이킷런으로 디코딩도 할 수 있으며, 이 경우 숫자로 인코딩 됐던 이름이 다시 글자로 돌아간다.
원핫 인코딩
# 레이블 인코딩 전 원본 데이터 불러오기
df = df_origin.copy()
# class 칼럼을 원핫 인코딩하기
pd.get_dummies(df['class'])
원핫 인코딩은 2진수를 이용하여 나타내는 방법이다.
10진수를 이용할 경우 분류는 되지만 AI가 번호에 순서나 높고 낮음 등이 있다고 생각 할 수 있기 때문에 그런 경우를 방지하기 위해 사용한다.
해당 코드에서는 class 값이 해당하는 곳에 true 혹은 1, 아닌곳에 false 혹은 0을 두어 구분한다.
# 원핫 인코딩 결과를 데이터에 반영하기
df = pd.get_dummies(df, columns=['class'])
df.head()
원핫 인코딩을 적용한 데이터이다.
class에 따라서 true/false로 구분되어 반영되었다.
# 판다스 원핫 인코딩 전 원본 데이터 불러오기
df = df_origin.copy()
# 사이킷런 패키지에서 OneHotEncoder 불러오기
from sklearn.preprocessing import OneHotEncoder
# OneHotEncoder로 원핫 인코딩하기
oh = OneHotEncoder()
# encoder = oh.fit_transform(df['class'].values.reshape(-1,1)).toarray()
encoder = oh.fit_transform(df[['class']]).toarray()
# 원핫 인코딩 결과를 데이터프레임으로 만들기
df_OneHot = pd.DataFrame(encoder, columns=['class_'+str(oh.categories_[0][i]) for i in range(len(oh.categories_[0]))])
# 원핫 인코딩 결과를 원본 데이터에 붙여넣기
df1 = pd.concat([df, df_OneHot], axis=1)
df1.head()
원핫 인코딩으로 얻은 결과를 바탕으로 2차원 배열 형태로 데이터에 붙여넣었다.
정규화하기
# 원핫 인코딩 전 원본 데이터 불러오기
df = df_origin.copy()
# 수치형 데이터만 분리하여 데이터프레임 만들기
df_num = df[['duration', 'days_left', 'price']]
# 정규화 수식 적용하기
df_num = (df_num - df_num.min()) / (df_num.max() - df_num.min())
df_num.head()
데이터 범위를 0~1 사이로 변환해서 데이터 분포율을 조정하는 방법이다.
min-max Scaling을 이용하여 정규화를 실행하여 중간값 0.5를 기준으로 전체데이터에서 어느정도 위치인지 알려준다.
df_num.describe()
describe를 이용해 살펴보면 min은 0, max는 1인 값으로 정규화가 되어있는걸 볼수있다.
단, min-max Scaling은 극단적인 이상치에 민감하니 꼭 이상치를 처리하고 정규화를 진행해야한다.
표준화하기
# 수치형 데이터만 분리하여 데이터프레임 만들기
df_num = df[['duration', 'days_left', 'price']]
# 표준화 수식 적용하기
df_num = (df_num - df_num.mean()) / df_num.std()
df_num.head()
정규화 산식을 이용하여 표준화를 적용했다.
# 요약 데이터로 표준화 적용 확인하기
df_num.describe()
평균이 0이고, 표준편차가 1인 표준 정규분포를 통해 정상적으로 표준화가 된 것을 확인 할 수 있다.
# 기존의 duration, days_left, price 칼럼 삭제하기
df = df.drop(['duration', 'days_left', 'price'], axis=1)
# 표준화된 duration, days_left, price 칼럼 붙이기
df = pd.concat([df, df_num], axis=1)
df.head()
기존의 칼럼을 제거하고 표준화된 데이터를 붙인다.
변수 선택하기
하나의 데이터로 여러개의 새로운 칼럼 만들기
# 항공기 기종을 제조사 코드와 모델명으로 분리하는 split_flight 함수 만들기
def split_flight(flight) :
# "-" 문자를 기준으로 앞쪽을 제조사 코드로 저장
manufacture = flight.split("-")[0]
# "-" 문자를 기준으로 뒤쪽을 모델명으로 저장
model = flight.split("-")[1]
# 제조사 코드와 모델명을 리턴
return manufacture, model
# df['flight]를 split_flight 함수의 파라미터로 넣어 실행하는 lmabda, apply를 적용하여 제조사 코드와 모델명 반환하기
# zip 함수를 사용하여 튜플로 묶어 df['manufacture'], df['model_num']에 저장하기
df['manufacture'], df['model_num'] = zip(*df['flight'].apply(lambda x : split_flight(x)))
df.head()
flight를 이용하여 -를 기준으로 앞과 뒤의 이름을 잘라내어 2개의 데이터로 만들었다.
여러개의 데이터로 하나의 새로운 칼럼 만들기
# source_city, desination_city를 튜플로 묶어 route 칼럼 생성하기
df['route'] = df.apply(lambda x : (x['source_city'], x['destination_city']), axis=1)
df.head()
이번에는 출발지와 도착지를 하나로 묶어 새로운 칼럼으로 만들었다.
df.drop(['manufacture', 'model_num'], axis=1).head()