사례 기반 선형 회귀 모델링
건강검진 데이터에서 'LDL 콜레스테롤' 수치를 예측해보는 선형 회귀 모델 만들기
import pandas as pd
# 데이터 불러오기
df = pd.read_csv('./국민건강보험공단_건강검진정보_20211229.CSV', encoding='cp949')
# pandas display 옵션 조정을 통해 View 범위 확장하기
pd.set_option('display.max_columns', None) # display 옵션을 통한 전체 열 확장
# 데이터 확인하기(상위 5개)
df.head()
AI 학습에 사용할 데이터 원본
이 데이터에서 LDL 콜레스테롤 수치에 별로 관계 없는 치아, 시력, 청력과 관련된 데이터를 제거한다.
# 가설을 참고하여 데이터 일부 삭제하기
# 시력, 청력, 치아 관련 칼럼은 관계없다는 가정으로 열 제거하기
df.drop(['치아우식증유무', '치석', '시력(좌)', '시력(우)', '청력(좌)', '청력(우)', '구강검진 수검여부'], axis=1, inplace=True)
# 기준년도 칼럼 확인하기
print('기준년도 칼럼 확인')
df['기준년도'].value_counts()
그외에 불필요한 기준년도, 가입자 일련번호, 데이터 공개일자, 성별코드, 시도코드 또한 제거한다.
# 불필요한 데이터 삭제하기
df.drop(['기준년도', '가입자 일련번호', '데이터 공개일자', '성별코드', '시도코드'], axis=1, inplace=True)
# 별도의 test 데이터 추출하기
test = df[df['LDL 콜레스테롤'].isnull()]
# NaN 데이터 행 단위로 삭제하기
train = df.dropna(axis=0)
# 학습 데이터 확인하기
print('학습 데이터 확인')
train.head(1)

비교적 콜레스테롤 수치와 연관이 있다고 볼 수 있는 데이터만 간추렸다.
# 정답 데이터 생성하기
y = train['LDL 콜레스테롤']
# 학습 데이터 생성하기
x = train.drop('LDL 콜레스테롤', axis=1)
# validation set 추출을 위한 train-test_split 라이브러리 불러오기
from sklearn.model_selection import train_test_split
# scikit learn 예시 코드 비율대로 불러오기
X_train, X_test, y_train, y_test = train_test_split(
x, y, test_size=0.33, random_state=42)
# 학습/검증 데이터 확인하기
print('학습/검증 데이터 확인')
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
본격적인 학습 전에 머신러닝을 위해 AI에게 제공할 문제와 정답 데이터를 가져온다.
X는 문제, y는 답에 해당한다.
# 라이브러리 불러오기
from sklearn.linear_model import LinearRegression
# 모델 생성하기
reg = LinearRegression()
# 학습하기
reg.fit(X_train, y_train)
# 기울기와 절편 확인하기
print(f'''기울기 및 절편확인
기울기 확인 coef = {reg.coef_}
절편 확인 intercept = {reg.intercept_}''')
데이터를 가지고 AI를 학습시킨다.
선형 모델링에서 기울기는 AI가 학습을 통해 변수 간의 영향력을 도출해낸 값이다.
예를 들어, 문제 X=일 때 정답 y=, X=일 때 y=였다면,
AI는 "입력 X와 출력 y 사이에 일정한 관계가 있구나"라는 패턴을 학습한다.
"1일 때 3이고, 3일 때 9이면, y는 X의 3배겠네!"→
이런 식으로 AI는 y = 3X라는 공식을 스스로 찾아낸다.
이렇게 도출된 모델을 기반으로, 학습되지 않은 X 값이 주어지면
AI는 그 X에 기울기 3을 곱해서 y를 예측한다.
즉, 기울기란 AI가 알아낸 예측 공식을 수치화한 것이며, 이를 그래프로 나타내면 데이터의 추세를 따르는 직선 형태로 시각화할 수 있다.
# 각각 데이터에 대해 가중치(or 회귀계수) 확인하기
print('전체에 대해서 가중치 확인')
for index ,columns in enumerate(X_train.columns):
print(f'{columns} = {reg.coef_[index]}')
가중치는 AI가 입력이 결과에 미치는 정도를 수치화하여 곱해주는것이다.
AI가 판단했을때 중요하다고 생각하면 높게 나오고, 별로 중요하지 않으면 0에 가깝게 나온다.
마이너스의 경우에는 중요하지 않은게 아니라 역으로 가중치를 가진다고 보면 된다.
from sklearn.metrics import root_mean_squared_error
# 예측하기
y_pred = reg.predict(X_test)
# 결과 검증을 위해 MSE 라이브러리 불러오기
# 최종적으로는 RMSE를 사용하기
rmse = root_mean_squared_error(y_test, y_pred)
# 주요 Feature 삭제 전 rmse 확인하기
print(f'''주요 Feature 삭제 전 rmse = {round(rmse, 3)}''')주요 Feature 삭제 전 rmse = 8.127
결과가 어느정도 정확한지 확인하기 위해서 도출된 값을 제곱하여 나타낸다.
AI의 추론에 의하면 '총 콜레스테롤 / HDL콜레스테롤 / 음주여부'가 LDL 콜레스테롤에 영향을 많이 준다고 판단했으니 실제로 그런지 확인하기 위한 과정이다.
# 주요 Feature 삭제하기
x = x.drop(['총 콜레스테롤', '트리글리세라이드', 'HDL 콜레스테롤'], axis=1)
# scikit learn 예시 코드 비율대로 불러오기
X_train, X_test, y_train, y_test = train_test_split(
x, y, test_size=0.33, random_state=42)# 선형 회귀 재생성 및 학습하기
lr = LinearRegression()
lr.fit(X_train, y_train)
# 각각 데이터에 대해 가중치(또는 회귀계수) 확인하기
print(f'''coef
{lr.coef_}
intercept
{lr.intercept_}''')
AI가 중요하다고 판단했던 요소들을 삭제한 후 도출된 값이다.
# 검증 데이터로 예측하기
y_pred = lr.predict(X_test)
# 각각 데이터에 대해 가중치(또는 회귀계수) 확인하기
print('가중치 확인')
for index, columns in enumerate(X_train.columns):
print(f'{columns} = {reg.coef_[index]}')
from sklearn.metrics import root_mean_squared_error
# 주요 Feature 삭제 후 RMSE 확인하기
rmse_2 = root_mean_squared_error(y_test, y_pred)
# 가중치가 큰 특성을 삭제했을 때 영향을 많이 받는지 확인하기
print(f'''주요 Feature 삭제 후 rmse = {round(rmse_2, 3)}''')주요 Feature 삭제 후 rmse = 38.847
AI가 중요하다고 판단했던 요소를 삭제하기 전에 오차는 8.127, 삭제한 후에는 38.847의 오차를 가지는 것으로 보아 AI는 결과값을 도출하는데 핵심적인 피쳐를 잘 캐치했다는 것을 알 수있다.
로지스틱 회귀
시그모이드 함수 만들기
# numpy 라이브러리 및 그래프 라이브러리 불러오기
import numpy as np
import matplotlib.pyplot as plt
# Sigmoid 함수 작성하기
def sigmoid(x):
# numpy.exp() 함수는 밑이 자연상수 e인 지수함수 (e^x)로 변환
return 1 / (1 + np.exp(-x))
# 항수 테스트용 데이터 생성하기
test = np.array([-1, 0, 1])
# 작성된 함수 확인하기
print(sigmoid(test))[0.26894142 0.5 0.73105858]
# 그래프 적용을 위한 데이터 만들기
sigmoid_x = range(-6, 7)
sigmoid_y = sigmoid(np.array(sigmoid_x))
# 선 그래프 그리기
plt.plot(sigmoid_x, sigmoid_y, color='blue', linewidth=0.5)
# 백그라운드 모눈종이 설정하기
plt.rcParams['axes.grid']=True
# 선 굵기 설정하기
plt.axvline(x=0, color='black', linewidth=3)
# y축 범위 설정하기
plt.yticks([0,0.5,1])
plt.show()
-6부터 6까지 입력값들을 0과 1사이의 값으로 변환해주는 로지스틱 함수가 구현됐다.
실습하기
# 학습 데이터 생성하기
x_train = [3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]
y_train = [0,0,0,0,0,0,0,1,1,1,1,1,1,1,1]
# 추론을 위한 데이터 생성하기
x_test = [0,1,2,18,19]
y_test = [0,0,0,1,1]
# 학습 데이터에 의해 numpy로 변경 및 행을 열로 변경하기
x_train = np.array(x_train).reshape([-1,1])
y_train = np.array(y_train)
# 추론 데이터에 의해 numpy로 변경 및 행을 열로 변경하기
x_test = np.array(x_test).reshape([-1,1])
y_test = np.array(y_test)
# 데이터 확인하기
print(x_train)
print(y_train)
로지스틱 회귀를 실습하기 위한 데이터를 작성한다.
# 로지스틱 회귀 라이브러리 불러오기
from sklearn.linear_model import LogisticRegression
# 로지스틱 회귀 생성하기
logi_reg = LogisticRegression()
# 학습하기
logi_reg.fit(x_train, y_train)
# 역산을 위한 기울기와 절편이 있는지 확인하기
print('intercept : ', logi_reg.intercept_)
print('coef : ', logi_reg.coef_)
로지스틱 회귀를 만들기 위한 라이브러리를 불러오고, 기울기와 절편을 출력했다.
# 기울기와 절편을 수동으로 결과 만들기
odd = [] #
for i in x_train:
odd.append((logi_reg.coef_*i) + logi_reg.intercept_)
sigmoid_y = sigmoid(np.array(odd))
sigmoid_y = sigmoid_y.reshape(-1,1)
# 역산된 그래프 표시하기
plt.scatter(x_train, y_train, color='red')
plt.plot(np.array(x_train), sigmoid_y, color='blue')
plt.rcParams['axes.grid']=True
plt.yticks([0,0.5,1])
plt.ylim([-0.1,1.1]) # y축 범위 : [Ymin, Ymax]
plt.show()
기울기와 절편을 이용하여 그린 시그모이드 그래프가 데이터를 잘 표현하고 있다.
로지스틱 회귀와 선형 회귀 비교하기
# 선형 회귀 함수 불러오기
from sklearn.linear_model import LinearRegression
# 선형 회귀 생성하기
lr = LinearRegression()
# 학습하기
lr.fit(x_train, y_train)
# 수식 완성을 위한 coef와 intercept 확인하기
print('intercept : ', lr.intercept_)
print('coef : ', lr.coef_)
coef_intercept = x_train * lr.coef_[0] + lr.intercept_
plt.scatter(x_train, y_train, color='red')
plt.plot(np.array(x_train), coef_intercept, color='green')
plt.plot(np.array(x_train), sigmoid_y, color='blue')
plt.rcParams['axes.grid']=True
plt.show()
print(logi_reg.score(x_test,y_test))
print(lr.score(x_test, y_test))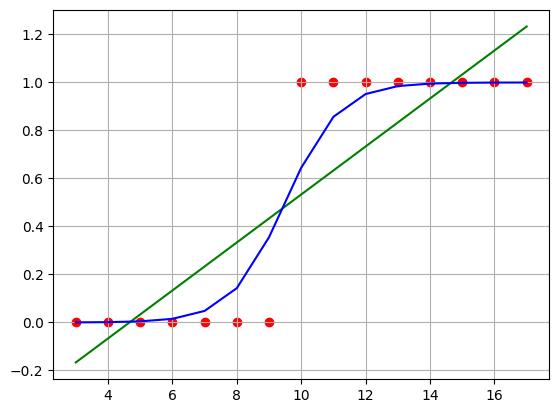
1.0
0.3981481481481479
빨간색 점이 예측값이고, 초록색선이 AI가 유추한 값, 파란색 선은 로지스틱 회귀가 적용된 선이다.
이 그래프로 알수 있는것은 빨간 점이 0 또는 1인 이진수 형태일때는 선형 회귀는 기울기는 완벽하게 캐치할수 있지만, 구조의 한계로 인해 정확도는 약 40% 정도 수준밖에 나오지 못한다.