앙상블
다수의 기본 모델을 생성하고 결합하여 하나의 새로운 모델을 생성하는 것이다.
여러 모델을 결합하므로 단일 모델보다 일반적으로 성능이 우수하고, 편향과 분산을 적절히 고려하기 때문에 과적합 방지에 용이하다.
보팅
보팅은 각각 다른 알고리즘을 이용해 모델을 결합하는 방식으로, 여러 모델의 결과를 기반으로 투표에 의해 결과를 도출한다.
보팅은 하드보팅과 소프트보팅으로 구분되며, 하드보팅은 각 모델의 결과 중 가장 많이 분류된 결과로 최종 결과를 선정하고, 소프트보팅은 각 모델별 예측한 확률값의 평균으로 최종값을 선정한다.
배깅
배깅은 부트스트랩 기반 샘플링 기법을 통해 하나의 알고리즘을 학습하여 생성된 여러 모델의 결과를 결합하는 알고리즘이다.
배깅은 먼저 학습 데이터로 부터 부트스트랩 샘플링을 진행하여 부트스트랩 데이터를 생성하고, 각 부트스트랩 데이터로 다수의 개별 모델을 학습한다. 마지막으로 최종 예측을 위해 보팅을 진행한다.
배깅은 복원 샘플링을 통해 최종 모델의 분산을 중여줌으로써 예측력을 향상시키고, 병렬 학습이 가능하다는 장점이 있다.
부스팅
예측력이 약한 모델 여러 개를 순차적으로 연결하여 예측력이 강한 모델을 만드는 방법이다.
부스팅은 모델을 직렬로 결합하여 앞선 모델이 예측한 것 중 틀린 데이터에 가중치를 부여하여 틀린 데이터를 더 잘 맞히도록 학습한다.
먼저 학습 데이터의 관측치를 동일한 가중치로 세팅하여 학습을 진행하고 모델 예측을 수행한 후 오분류된 관측치에는 높은 가중치를 부여하고, 정분류된 관측치에는 낮은 가중치를 부여하여 학습 데이터를 다시 샘플링하고 학습하는 과정을 반복한다. 마지막으로 각 모델의 예측 결과를 결합할 때 각 모델에 가중치를 주어 가중 평균을 계산하는 방식으로 최종값을 출력한다.
트리 기반 머신러닝 모델
의사결정 나무
데이터를 특징에 따라 조건 분기해서 트리 구조로 나누는 모델로 리프 노드에 최종 예측값을 저장한다.
직관적이고 해석이 쉽지만 과적합에 취약하고 단일 모델이다.
랜덤 포레스트
여러 개의 의사결정 나무를 학습시켜 앙상블 하는 배깅 방식으로 각 트리는 랜덤하게 선택된 데이터와 특성을 통해 학습하고 최종 예측은 다수결(분류) 또는 평균(회귀)이다.
의사결정 나무의 단점을 보완하여 과적합이 줄어들고 학습 속도가 빠르고 병렬 처리가 가능하며 해석성은 떨어지지만 성능이 우수하다.
그래디언트 부스팅
여러 개의 얕은 의사결정 나무를 순차적으로 학습하여 오류를 줄여나가는 방식으로 각 단계에서 이전 예측이 틀린 부분을 보완한다.
예측 성능이 매우 좋지만 과적합을 방지 하려면 튜닝이 필요하고 학습이 느리고 순차적이라 병렬 처리가 어렵다.
의사결정 나무, 랜덤 포레스트 비교
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
dct = DecisionTreeClassifier(random_state=0)
dct.fit(X_train, y_train)
acc_train_dct = dct.score(X_train, y_train)
acc_test_dct = dct.score(X_test, y_test)
print(f'''학습결과 = {acc_train_dct}, 검증 결과 = {acc_test_dct}''')rfc = RandomForestClassifier(random_state=0)
rfc.fit(X_train, y_train)
acc_train_rfc = rfc.score(X_train, y_train)
acc_test_rfc = rfc.score(X_test, y_test)
print(f'''의사결정나무 : train_acc = {round(acc_train_dct,3)}, test_acc = {round(acc_test_dct,3)}''')
print(f'''랜덤 포레스트 : train_acc = {round(acc_train_rfc,3)}, test_acc = {round(acc_test_rfc,3)}''')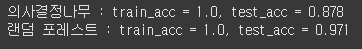
import matplotlib.pyplot as plt
acc_list_x = ['dct_train', 'dct_test', 'rfc_train', 'rfc_test']
acc_list_y = [acc_train_dct, acc_test_dct, acc_train_rfc, acc_test_rfc]
colors = ['orange', 'orange', 'blue', 'blue']
plt.bar(acc_list_x, acc_list_y, color=colors)
plt.show()
의사결정 나무와 랜덤 포레스트를 비교했을 때 상대적으로 랜덤 포레스트가 더 높은 정확성을 보인다는 것을 알수있다.
그래디언트 부스팅
from tensorflow.keras.datasets.mnist import load_data
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = load_data()
x_train = x_train[:2000]
y_train = y_train[:2000]
x_test = x_test[:2000]
y_test = y_test[:2000]
plt.imshow(x_train[7], cmap='Greys')
plt.show()
plt.imshow(x_train[1], cmap='Greys')
plt.show()

X_train = x_train.reshape(-1, 784)
X_test = x_test.reshape(-1, 784)from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
dct = DecisionTreeClassifier(random_state=0)
dct.fit(X_train, y_train)
acc_train_dct = dct.score(X_train, y_train)
acc_test_dct = dct.score(X_test, y_test)
rfc = RandomForestClassifier(random_state=0)
rfc.fit(X_train, y_train)
acc_train_rfc = rfc.score(X_train, y_train)
acc_test_rfc = rfc.score(X_test, y_test)
gbc = GradientBoostingClassifier(random_state=0)
gbc.fit(X_train, y_train)
acc_train_gbc = gbc.score(X_train, y_train)
acc_test_gbc = gbc.score(X_test, y_test)
print(f'''의사결정나무 : train_acc = {round(acc_train_dct,3)}, test_acc = {round(acc_test_dct,3)}''')
print(f'''랜덤 포레스트 : train_acc = {round(acc_train_rfc,3)}, test_acc = {round(acc_test_rfc,3)}''')
print(f'''랜덤 포레스트 : train_acc = {round(acc_train_gbc,3)}, test_acc = {round(acc_test_gbc,3)}''')

그래디언트 부스팅의 시험 데이터세트에 대한 성능이 의사결정나무보다 좋지만, 랜덤 포레스트 보다는 떨어지는 결과를 볼수있다.