심층신경망으로 항공사 고객 만족 분류 모델 구혈 실습하기
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')df = pd.read_csv('./Invistico_Airline.csv')
df.info()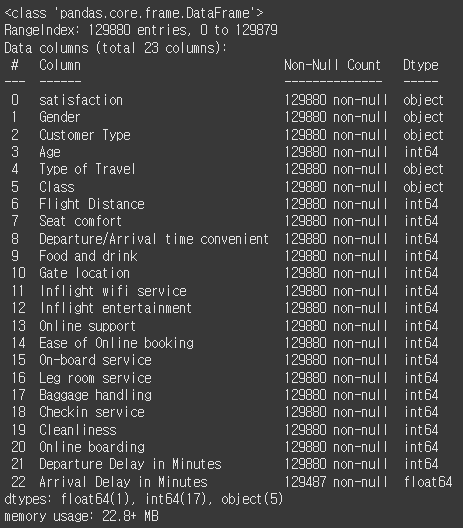
df.head()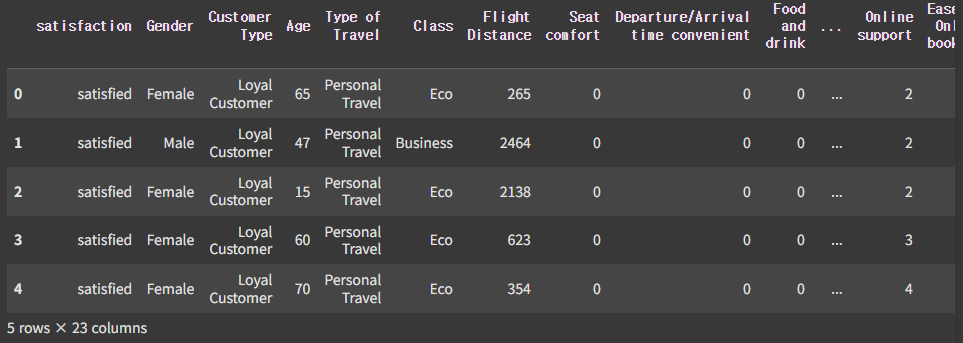
df.describe()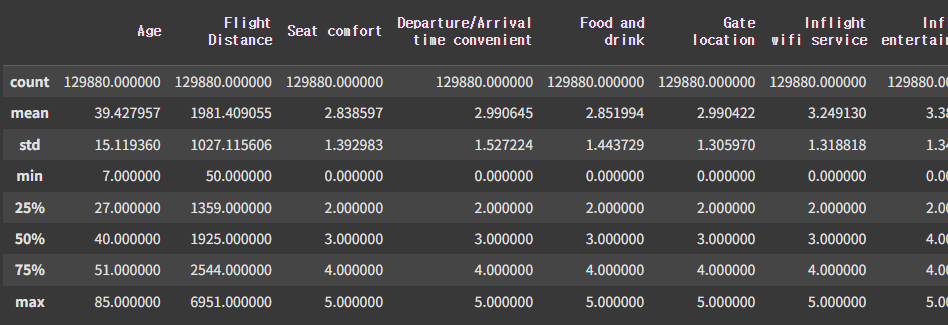
df.isnull().sum()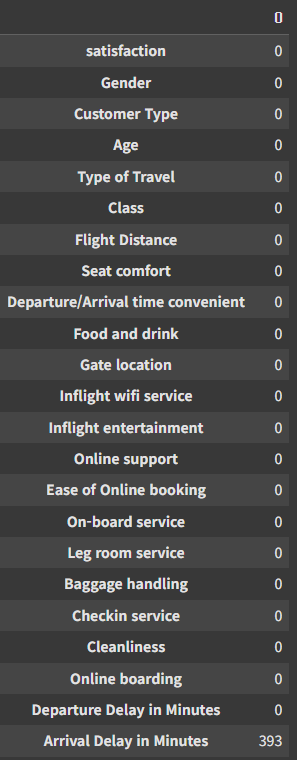
데이터를 불러와서 살펴보니 총 데이터는 129880개고 칼럼은 23개, 결측치는 393개가 있는걸 알수있다.
from sklearn.impute import SimpleImputer
mean_imputer = SimpleImputer(strategy='mean')
df['Arrival Delay in Minutes'] = mean_imputer.fit_transform(df[['Arrival Delay in Minutes']])
cols = ['satisfaction', 'Gender', 'Customer Type', 'Type of Travel', 'Class']
df[cols] = df[cols].astype(str)
df['satisfaction'].replace(['dissatisfied', 'satisfied'], [0,1], inplace=True)
categories = pd.Categorical(
df['Class'],
categories = ['Eco', 'Eco Plus', 'Business'],
ordered=True)
labels, uniqye = pd.factorize(categories, sort=True)
df['Class'] = labels
cat_cols = ['Gender', 'Customer Type', 'Type of Travel']
df = pd.get_dummies(df, columns=cat_cols)
df.head()
가져온 데이터를 필요한 부분을 전처리하는 과정이다.
좌석등급을 에코, 에코플러스, 비즈니스 순으로 수치형으로 인코딩 하고, 성별, 고객 유형, 여행 유형을 원핫 인코딩을 적용해서 표현했다.
df.dtypes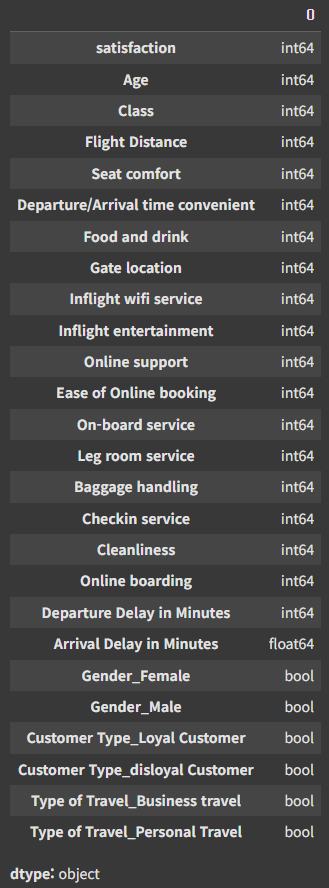
전처리 한 결과를 보기위해 데이터타입을 조회했다.
from sklearn.model_selection import train_test_split
X = df.drop(['satisfaction'], axis=1)
y = df['satisfaction'].reset_index(drop=True)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print(f'훈련 데이터세트 크기 : X_train {X_train.shape}, y_train {y_train.shape}')
print(f'검증 데이터세트 크기 : X_val {X_val.shape}, y_val {y_val.shape}')
본격적으로 훈련을 하기 위해 훈련 데이터와 검증 데이터를 8:2로 나눠준다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_val = scaler.transform(X_val)
print(X_train)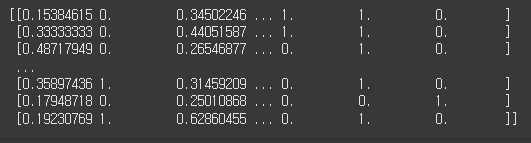
딥러닝이 잘 동작할 수 있게끔 데이터 스케일링을 통해 모든 특성의 범위를 유사하게 만들어준다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Input, Dense, Dropout
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import random
tf.random.set_seed(42)
np.random.seed(42)
random.seed(42)
initializer = tf.keras.initializers.GlorotUniform(seed=42)
model = Sequential()
model.add(Dense(32, activation='relu', input_shape=(25,), kernel_initializer=initializer))
model.add(Dense(64, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))입력 데이터 25개, 은닉층 여러 개, 출력인 1개인 이진 분류를 위해 심층신경망 모델을 구성한다.
model.summary()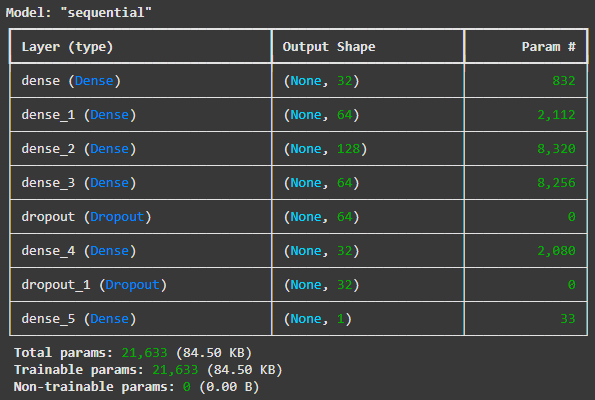
모델과 파라미터의 수를 확인해보면 모델은 총 8개의 층으로 구성되어있고, 학습해야 할 총 파라미터 수는 21633개이다.
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])옵티마이저를 아담, 모델 성능 평가 메트릭은 정확도, 이진분류 모델이기 때문에 손실함수는 binary_crossentropy를 사용한다.
es = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1, restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=100, batch_size=128, verbose=1, validation_data=(X_val, y_val), callbacks=[es])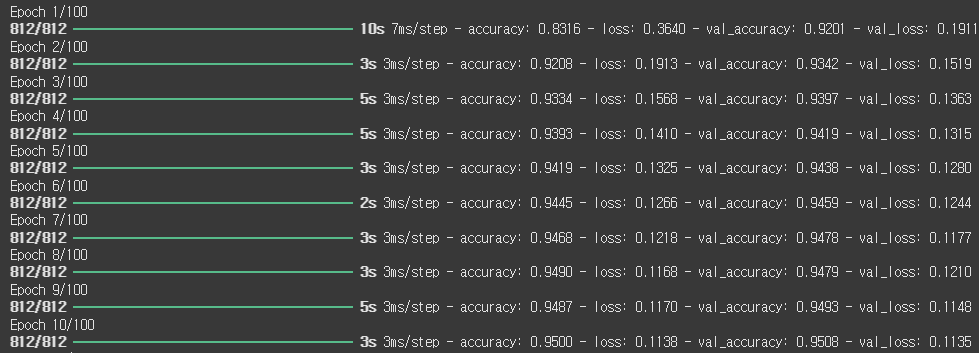
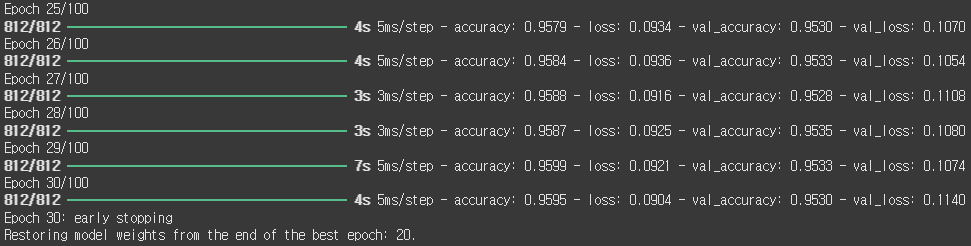
위의 학습은 100번이 진행되야 하지만 validation loss가 10번 이상 개선되지 않았기 때문에 학습을 종료했고 가장 성능이 좋았던 20번을 가중치로 두었다.
또한 훈련 과정의 loss와 accuracy를 history에 저장했다.
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(['Train', 'Validation'], loc = 'lower right')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(['Train', 'Validation'], loc = 'upper right')
plt.show()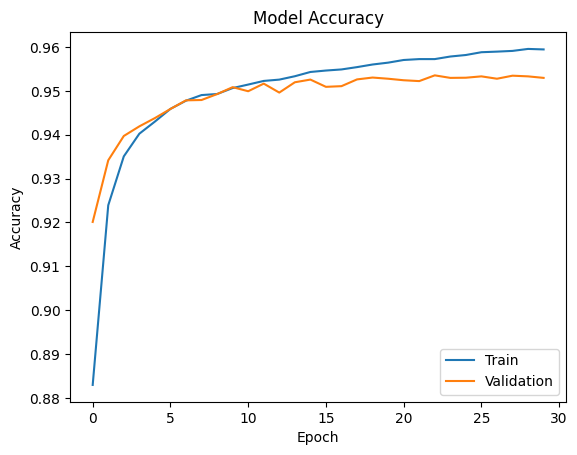
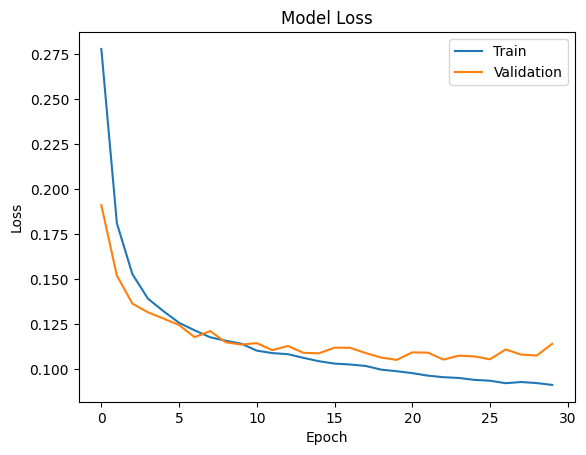
그래프를 확인해보면 모델의 정확성은 학습이 진행됨에 따라 점점 증가하고, 손실값은 점점 줄어드는걸 확인할 수 있다.